
このレクチャーでは、文字列を定義するときの記法として、raw文字・トリプルクォーテーション・その他の文字の表記方法を学習します。
Table of Contents(目次)
raw文字
raw文字のrawとは日本語で、
- 生の
- 加工されていない
- そのままの
という意味があります。Pythonのraw文字は、『エスケープ処理をせずに、書いたまま(=生のまま)使う文字列』になります。
raw文字定義
前回のレクチャーで紹介した、ディレクトリの記法を例に、raw文字で書くとどうなるのかを紹介します。
desktop_path = 'c:\\Users\\nico\\Desktop'
desktop_path_raw = r'c:\Users\nico\Desktop'

2行目はraw文字ですが、raw文字を定義する時は、クォーテーションの前に
rを付けてr'...'の形で記述します。(大文字のRでも機能します。) raw文字で定義すると Pythonが『これは記述されている通り扱う文字列だ』と理解し、\をそのまま文字として扱ってくれるようになるため、エスケープシーケンスを気にせずにバックスラッシュ1本で記述することができます。
VisualStudioCodeの場合は、raw文字と認識されると文字色が赤くなります。一部、文字の色が黄色くなっている所がありますが、無視して大丈夫です。(厳密には、正規表現に関わる部分の色が変わっているのですが、正規表現を学習するのはまだまだ先の話ですので、ここでは『エスケープ処理を気にせずに記述することが出来る』と覚えて頂ければ問題ありません。)
各行で代入した文字列をprint出力すると、下図のようになります。

両方とも、改行などのエスケープ処理されずに、ディレクトリ情報が格納されていることが確認できます。
raw文字の仕組み
raw文字がどのような仕組みになっているか確認してみます。変数が持っている文字列情報を、素のまま表示させるのに使える"repr"関数がありますので、これを使います。
次のコードを実行してみます。
desktop_path_raw = r'c:\Users\nico\Desktop'
print(repr(desktop_path_raw)) # "repr"で文字情報が素の状態で出力される
実行すると、下図のような結果が表示されたかと思います。

1行目のraw文字が宣言された時点で、バックスラッシュの部分にもう1本バックスラッシュが自動的に付与されているのが確認できます。つまり、r'...'記法で文字列を定義した時に、Pythonは『通常の文字列を定義した時と同じデータに変換して、変数へ代入する』という処理を行ってくれていることになります。そのお陰で、プログラマーはわざわざバックスラッシュを2本書かずに記述することができるのです。
トリプルクォーテーション
次のように、複数行にまたがった文字列の塊があったとします。
I am Nico.
I am Nancy.
I am Noah.
これを改行も含めて文字列で定義しようとすると、改行のエスケープシーケンスを使い、次のように記述することができます。
introductions = 'I am Nico.\nI am Nancy.\nI am Noah.'
この方法でも定義できるのですが、文字数や行数が多い場合は大変です。行数が多いと、どこで改行させないといけないのかを確認しながら入力しなくてはならず、大変でしょう。そのような、複数行の文字列の塊がある場合に使うと便利なのがトリプルクォーテーションです。
トリプルクォーテーションの定義
文字の塊の最初と最後に、シングル/ダブルクォーテーションを3つ並べて記述します。('''もしくは""")
次のように記述します。
'''
I am Nico.
I am Nancy.
I am Noah.
'''
これで、'''で挟まれた部分が文字列として認識されます。(ダブル"""の場合も同様。)
この文字列を変数"s"へ代入し、print出力してみます。
s = '''
I am Nico.
I am Nancy.
I am Noah.
'''
print('===============')
print(s)
print('===============')
分かりやすいように、'==============='で、print出力を挟んでみました。結果は下図のようになります。
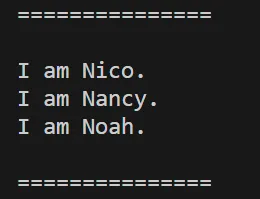
まず確認できるのは、文字列を定義した時と同じように改行されているということです。これまでは改行のエスケープシーケンスを使わないといけなかったのですが、トリプルクォーテーションではその必要はありません。
次に気になるのはI am Nico.の上部とI am Noah.の下部に改行が入っていることです。トリプルクォーテーションでは、'''より後に現れる改行は、全て素直にトレースしてしまいます。
不要な改行を取り除く
改善策としては2つあり、どちらかを選択することになります。
- 改行を入れたくない場所では改行せずに続けて記述する(
'''に続けてI am Nico.を記述し、I am Noah.の後で改行せずに'''を記述する) - 改行コードを無視するエスケープシーケンスを使用する
(1)をコードで書くと次のようになります。
s = '''I am Nico.
I am Nancy.
I am Noah.'''
print('===============')
print(s)
print('===============')
(2)をコードで書くと次のようになります。
s = '''\
I am Nico.
I am Nancy.
I am Noah.\
'''
print('===============')
print(s)
print('===============')
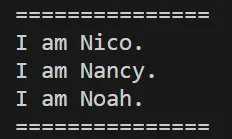
(2)では、改行させたくない場所(最初の'''の後とNoah.の後)に、バックスラッシュを置いています。バックスラッシュの直後に改行がある場合は、『バックスラッシュと改行が無視される』というエスケープシーケンスの効果が表れます。
(1)と(2)のいずれの場合も下図のように不要な改行のない文字列を得ることが出来ます。
文字列の中にシングル/ダブルクォーテーションが存在する場合
トリプルクォーテーションの中であれば、エスケープシーケンスを使わずにシングル/ダブルクォーテーションを使うことが出来ます。先ほどのコードの、I amの部分をI'mに書き直してみます。
s = '''\
I'm Nico.
I'm Nancy.
I'm Noah.\
'''
print(s)
上記のように、エスケープシーケンス無しで記述してもエラーになりません。Pythonは、'''で文字列が始まった後、次の'''が出てくるまでの間の'や"は、全て『文字』として扱います。
トリプルクォーテーションの仕組み
トリプルクォーテーションでも、どのような仕組みになっているか確認してみます。
次のコードを実行してみます。
s = '''\
I'm Nico.
I'm Nancy.
I'm Noah.'''
print(repr(s))
実行すると、下図のような結果が表示されたかと思います。

\nが挿入されています。raw文字の時と同じように、通常の文字列の定義の時と同じような形へデータを整えてくれているのが確認できます。
その他の文字の表記方法
1行が長い文字列の場合
1行が長くて途中で改行させたくない文字列があった場合に、見やすく文字列の定義を行うことが出来る方法をご紹介します。
s = "Hello, I'm Nico. It's a great honor to meet you all. I'm originally from Los Angeles, and now I live in New York."
上記コードのように1行が長くなる場合に、次のように書き換えることが出来ます。
s = ("Hello, I'm Nico. "
"It's a great honor to meet you all. "
"I'm originally from Los Angeles, and now I live in New York.")
print(s)
上記コードを実行すると、下図のように途中で改行されていない文章を出力することが出来ます。

上記のように、1行の文章を行に分けて文字列定義するときの手順は次の通りです。
- 適度な長さで文章を改行する
- 各行をクォーテーションで挟む
- 先頭と最後を丸カッコで囲う
補足として、トリプルクォーテーションで定義する場合の書き方も紹介します。
s = '''\
Hello, I'm Nico.\
It's a great honor to meet you all.\
I'm originally from Los Angeles, and now I live in New York.\
'''
print(s)
トリプルクォーテーションの場合は改行が自動的に付いてしまうので、改行を阻止するために各行の最後にバックスラッシュを付けなければなりません。
どちらの方法を使うかは、定義する文章の内容次第で使い分けるのが良いかと思います。






