
Table of Contents(目次)
文字列のメソッド
メソッドとは
このレクチャーでは、文字列のメソッドについて学習します。
メソッドとは『データに用意されている関数』で、そのデータに対して何か処理を行うために使います。例えば、『タオル("towel")』というデータがあったとして、それを『洗う』『たたむ』といった行動(関数の処理)ができます。他には、『使用回数をインクリメントする』や『現在の使用回数を取得する』といった、そのデータ(towel)に関する記録を登録したり、記録を参照するという処理が用意されていることがあります。
towel.wash() # 『洗う』動作(関数)を実行する
towel.fold() # 『たたむ』動作(関数)を実行する
towel.increment_usage() # 『"使用回数"を1加算する』
towel.get_usage_count() # 『現在の使用回数を取得する』
この wash(), fold(), increment_usage(), get_usage_count() のように、データにくっついて使う関数のことをメソッドと呼びます。
今回のレクチャーでは、String型のメソッドを学習します。
メソッドと関数の違い
メソッドと関数の違いは次の通りです。Pythonではこの違いを細かく知らなくても大丈夫ですので、軽く確認する程度で問題ありません。
| 用語 | 対象 | 書式 | 使用例 |
|---|---|---|---|
| 関数(function) | 単体の処理 | 関数名() | print() |
| メソッド(method) | データに用意されている関数 | 変数名.メソッド名()'文字列の定義'.メソッド名() | text.upper()"I'm Nico, 10.".upper() |
text.upper()
1つ目のメソッドは、upper()です。これは、文字列のアルファベットを大文字に変換します。次のコードを実行してみましょう。
text = "I'm Nico, 10."
new_text = text.upper()
print(new_text)
結果は、I'M NICO, 10.になります。全てのアルファベットが大文字になります。他の数字や記号はそのままです。
メソッドはこのように、データに対して処理を行うものになります。upper()メソッドはString型に用意されている関数ですので、データがString型であればテキストの内容は問わずupper()メソッドを使うことができます。
upper()メソッドを使うと大文字に変換された文字列のデータが返されるので、これを"new_text"変数へ代入し、print出力します。
text.lower()
lower()は、文字列のアルファベットを小文字に変換します。
text = "I'm Nico, 10."
new_text = text.lower()
print(new_text)
結果は、i'm nico, 10.になります。全てのアルファベットが小文字になります。他の数字や記号はそのままです。
text.title()
title()は、文字列の各単語の先頭を大文字に、その他を小文字に変換します。文章をタイトル風に整えるときに使います。
text = "i'm nico, 10."
new_text = text.title()
print(new_text)
結果は、I'M Nico, 10.になります。1番最初の文字や空白の直後の先頭文字以外にも、シングルクォーテーションのような記号の直後の文字も大文字に変換されるような挙動になります。
text.capitalize()
capitalize()は、文字列の1番先頭の1文字だけを大文字にし、その他を小文字に変換します。文章の最初を正しい書き方に直すときに使います。
text = "i'm Nico, 10."
new_text = text.capitalize()
print(new_text)
結果は、I'm nico, 10.になります。最初の単語以外はすべて小文字になるため、固有名詞が途中にある場合は再度調整が必要です。今回はNicoがnicoになってしまいます。
title()やcapitalize()などのメソッドは、使いどころがマッチすれば便利な関数ですが、必ずしもプログラマーの意図するような挙動になるとは限りません。例えば、title()の場合はシングルクォーテーションの直後の文字が大文字に変化したり、capitalize()は固有名詞の先頭文字を小文字に変化させてしまいます。
そのため、プログラマーは必要に応じて、書き方を工夫してコードを書かなくてはなりません。例えば、『1番最初の文字を大文字に変換し、それ以外は一切変換させない』という挙動を、どのような文字列であっても実現させたい場合は、次のように書きます。
text = "i'm Nico, 10."
new_text = text[0].upper() + text[1:]
print(new_text) # I'm Nico, 10.
上記コードは、文字列のスライスの応用で、1番最初([0])の文字をupper()で大文字に変換し、2文字目以降の文字列([1:])を+演算子を使って結合しています。こうすることで、『1番最初の文字を大文字に変換し、それ以外は一切変換させない』という挙動を確実なものにします。
Pythonは便利な関数やメソッドが用意されていますが、必ずしもプログラマーが求めている完璧な挙動をするわけではありません。ですので、公式ドキュメントで仕様を確認したり、プログラムの動作テストを行い、想定している挙動にならない可能性がある場合は、代替案を考えて問題なく動作するようにコードを書きなおす必要があります。
text.strip()/ text.lstrip()/ text.rstrip()
strip()は、変数に代入されている文字列の前後にある空白や改行を取り除きます。ユーザー入力やファイルから読み込んだ文字列を整えるときに使います。
lstrip()は、変数に代入されている文字列の先頭(左側)の空白や改行を取り除きます。先頭側だけ不要な空白/改行を消したいときに使います。(メソッド名の先頭に、Left(左)の"l"が付いています。)
rstrip()は、変数に代入されている文字列の末尾(右側)の空白や改行を取り除きます。末尾側だけ不要な空白/改行を消したいときに使います。(メソッド名の先頭に、Right(右)の"r"が付いています。)
text = " I'm Nico, 10. "
new_text_strip = text.strip()
new_text_lstrip = text.lstrip()
new_text_rstrip = text.rstrip()
print(new_text_strip + ':(strip)') # "I'm Nico, 10."
print(new_text_lstrip + ':(lstrip)') # "I'm Nico, 10. "
print(new_text_rstrip + ':(rstrip)') # " I'm Nico, 10."
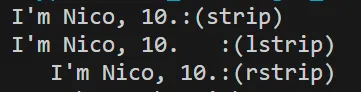
strip(), lstrip(), rstrip()それぞれの結果は上図のようになります。文字列の前後の空白・改行のみが削除され、中間の空白はそのまま残っていることを確認してください。
text.replace("old", "new")
text.replace() の基本
replace("old", "new")は、文字や単語を修正・変換するときに使います。文字列の、部分文字列"old"を全て"new"に置き換えます。"old"と"new"は丸カッコ内でカンマで区切って指定します。尚、部分文字列"old"の検索は、大文字・小文字を区別します。
text = 'Can you can a can as a canner can can a can?' # 缶詰職人が缶を缶詰にするように、缶を缶詰にすることができますか?
new_text = text.replace('can', 'X')
print(new_text) # Can you X a X as a Xner X X a X?
結果は、Can you X a X as a Xner X X a X?になります。"can"の検索にマッチした部分が全て"X"に置換されます。
尚、文字列の先頭の"Can"は、"C"が大文字のため検索にマッチしませんでした。先頭の"Can"にもマッチさせたい場合は、lower()を組み合わせて使用することで、大文字・小文字区別なく処理することができます。
text.replace() の置き換える回数
replace()メソッドは、置き換える回数を指定することもできます。text.replace('old', 'new', count)の書式で指定します。
text = 'Can you can a can as a canner can can a can?'
text_lower = text.lower()
new_text = text_lower.replace('can', 'X', 2)
print(new_text) # X you X a can as a canner can can a can?
上記コードは、replace()メソッドを使用する前にlower()メソッドで全て小文字に変換しています。ですので、今回は先頭の"Can"も置換が行われます。3行目のrepalce()メソッドの丸カッコ内の最後に、置き換える回数を指定しています。
実行結果はX you X a can as a canner can can a can?となり、"can"にマッチしたした部分が、先頭から2か所置き換えられています。
text.startswith("prefix")/ text.endswith("suffix")
startswith("prefix")は、文字列が、部分文字列"prefix"から始まるかどうかを確認したいときに使います。文字列が部分文字列"prefix"で始まる時はTrueを、違う場合はFalseを返します。
endswith("suffix")は、文字列が、部分文字列"suffix"で終わるかどうかを確認したいときに使います。文字列が部分文字列"suffix"で終わる時はTrueを、違う場合はFalseを返します。
True, Flaseは、bool型という正誤を表すデータになります。Trueは正、Falseは誤を表します。
例えば、変数"num"の数値が10より大きいかどうかをnum > 10という条件で調べ、numが10より大きければTrueを、10以下だった場合はFalseを返します。この正誤の結果に応じて、異なる処理を実行させることができるようになります。
詳しくは、専用のレクチャーで解説します。
# startswith
text = "I'm Nico, 10."
result1 = text.startswith("I'm")
print(result1) # True
result2 = text.startswith("I am")
print(result2) # False
# endswith
text = "I'm Nico, 10."
result1 = text.endswith("!")
print(result1) # False
result2 = text.endswith("10.")
print(result2) # True
上記コードの結果ですが、
- 3行目のstartswithは、テキストが"I'm"から始まっているのでTrueを返します
- 5行目は、テキストが"I am"で始まっていないのでFalseを返します
- 10行目のendswithは、テキストが"!"で終わっていないのでFalseを返します
- 12行目は、テキストが"10."で終わっているのでTrueを返します
尚、startswith/endswithは、大文字・小文字を区別して判定します。
text.find("substring")/ text.rfind("substring")
find("substring")は、特定の単語や文字がどこにあるか調べたいときに使います。文字列の中から部分文字列"substring"が最初に現れる位置(要素番号)を返します。部分文字列が見つからない場合は"-1"を返します。
rfind("substring")は、部分文字列を右側(末尾側)から検索して、最初に見つかった位置(要素番号)を返します。(マッチした中の、1番若い要素番号が返されます。) 部分文字列が見つからない場合は"-1"を返します。同じ部分文字列が複数存在する可能性がある時に、最後に現れる位置を調べたいときに使います。
尚、find, rfindともに大文字・小文字を区別します。
text = 'Can you can a can...'
index1 = text.find('can')
print(index1) # 8
index2 = text.rfind('can')
print(index2) # 14
find()は、最初にマッチする[8][9][10]の"can"を発見し、その中で1番若い要素番号の[8]を結果として返します。(1番先頭の"Can"は大文字が含まれているためマッチしません。)
rfind()は、末尾から検索を行い、[14][15][16]の"can"を発見し、その中で1番若い要素番号の[14]を結果として返します。
| [0] | [1] | [2] | [3] | [4] | [5] | [6] | [7] | [8] | [9] | [10] | [11] | [12] | [13] | [14] | [15] | [16] | [17] | [18] | [19] |
C | a | n | | y | o | u | | c | a | n | | a | | c | a | n | . | . | . |
text.count("substring")
count("substring")は、文字列の中に部分文字列"substring"がいくつ含まれているかを数えて、その数を返します。特定の単語や文字の出現回数を調べたいときに使います。
text = 'Can you can a can as a canner can can a can?'
text_lower = text.lower()
result = text_lower.count('can')
print(result) # 7
上記コードは、lower()メソッドで全て小文字に変換しているので、先頭の"Can"も含めて、全部で7個の"can"が含まれているという結果を得られます。

![sec01 - 文字列のフォーマット [概要]](https://python101.tech/wp-content/uploads/2025/08/eyecatch_169-1-300x169.webp)




