![[コラム] Pythonの変数とデータの管理方法](https://python101.tech/wp-content/uploads/2025/08/eyecatch_187.webp)
このレクチャーでは、Pythonがどのように変数とデータを管理しているのかを学習します。
Table of Contents(目次)
数値/文字列の管理
数値の場合
まずは、数値が変数に代入された時、Pythonがどのようにデータを管理しているのか説明します。
次のようにnum1 = 5が実行されると、Pythonは数値5をメモリ上に確保します。
num1 = 5
数値5には、データのタイプとして整数型(int)が割り当てられ、id番号が付与されます。id番号は、Pythonがメモリ上でそのデータを一意に識別するためのものです。変数名"num1"は、このid番号を参照するためのラベルのようなもので、変数と値は紐づけられています。

次にnum2 = 5が実行されると、数値5は既に存在しているので、Pythonは既存の5を流用して、変数"num2"と数値5を紐づけて管理します。
num1 = 5
num2 = 5
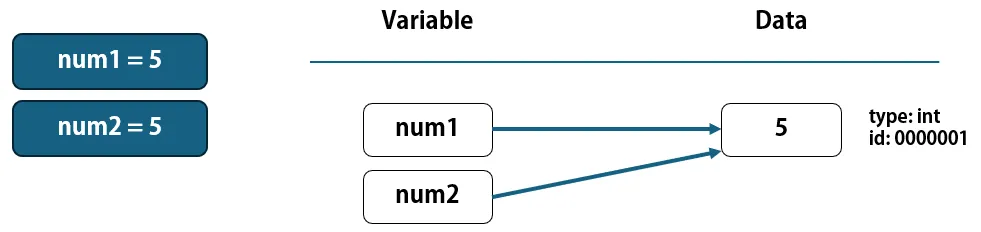
このように、データを新規に作らずに参照させる方法は、メモリの使用量を最低限に抑えることができるなどのメリットがあります。
この挙動は、num2 = num1が実行される時も同じ挙動になります。"num2"は"num1"が参照している値を、同じように参照します。
num1 = 5
num2 = num1
次に、num1 = 10が実行された場合の挙動を見ていきましょう。数値10はまだメモリ上に存在していないため、新しくデータが作成された後、"num1"の参照先が値10に切り替わります。
num1 = 5
num2 = 5 # or "num2 = num1"
num1 = 10
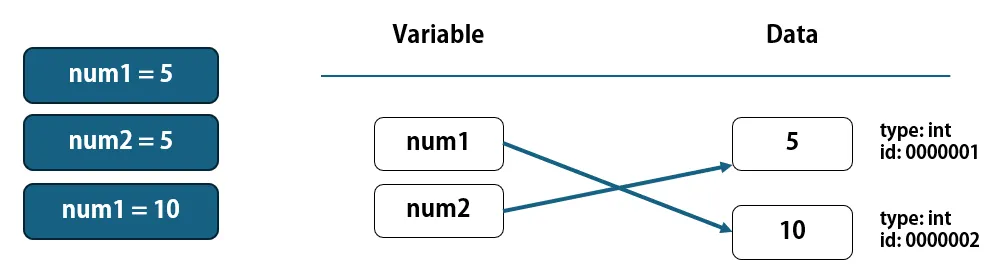
これが、Pythonのデータ管理の基本です。
文字列の場合
文字列の場合も基本的な考え方は同じです。次のようにコードを記述すると、同じid番号の文字列データへの紐づけが行われます。
str1 = 'Hello'
str2 = 'Hello'
しかし、文字列の生成方法が違うと、同じ文字の並びでも、違うデータとして管理される場合があります。
str1 = 'Hello'
str2 = '{}llo'.format('He') # 'Hello'
str3 = 'Hello World'[:5] # 'Hello'
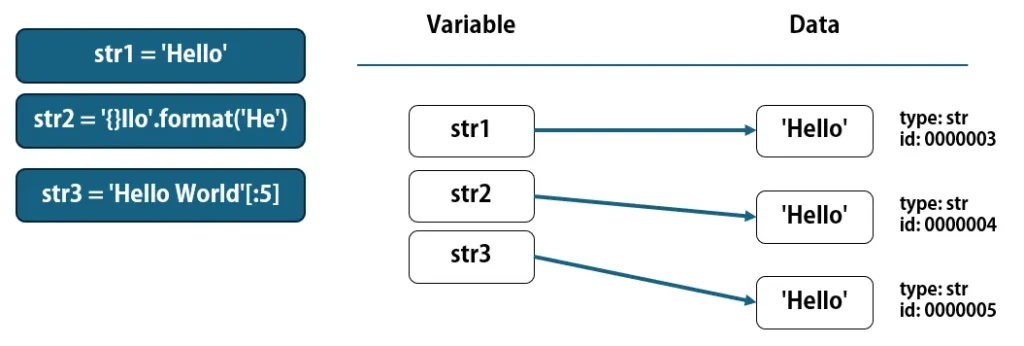
文字列の場合は、変数の参照先の違いによる問題が起こることは殆どありませんが、一応頭の片隅に置いておくと良いでしょう。
ここまでのまとめ
Pythonの内部では、変数とデータが生成され、それらを紐づけて管理されていることを説明しました。
これまで、『変数とは箱のようなもの』や『値を変数へ代入する』という言い回しを行ってきたため、これまでのイメージと、Pythonの内部的な処理との違いに驚かれたかもしれません。ただ、この事実が重要になる場面はそう多くはなく、問題となる場面はlistなどのオブジェクト(構造体)をコピーするような場面に限られます。そのため、今後も『変数へ代入する』という言い回しは使い続けつつ、データの管理について意識すべき場面で、その都度注意喚起を行っていきます。
listの管理の基本
ここからは、listのデータの管理の仕方について学習していきます。
まずは、listのデータ管理の構造を理解しましょう。
original_list = [1, 2, 3]
上記コードが実行されると、『listオブジェクト』が作られます。listは、実データを格納しているわけではなく、要素番号ごとにデータを参照して管理するモノです。
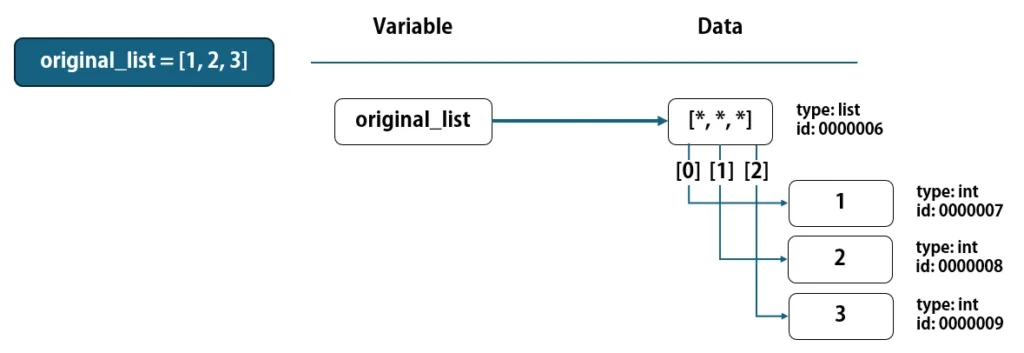
厳密には、上図のように要素番号ごとに数値のデータを参照して管理しているのですが、この書き方だと説明が複雑になるため、次からは下図のようにシンプルな書き方で説明します。

同じ要素を持つlistと変数との関係
同じlistオブジェクトを参照する例
ここまでの解説の通り、変数はlistオブジェクトを参照して管理します。次のようにコードを記述すると、それぞれの変数は同じデータを参照します。
original_list = [1, 2, 3]
copied_list = original_list
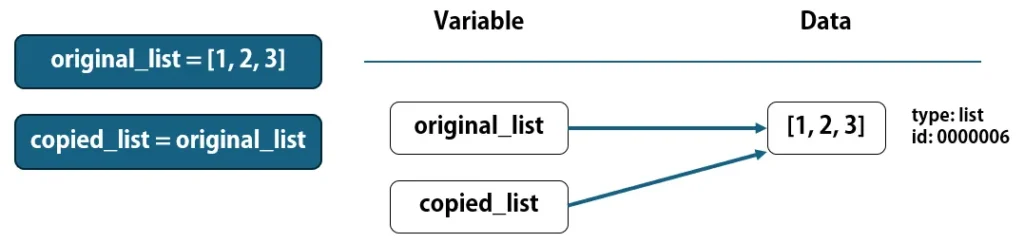
copied_list = original_listのように記述した時は、同じデータを参照することになります。
異なるlistオブジェクトを参照する例
ただし、次のようにデータを作成すると、同じ要素を持つlistを別データとして作成・参照させることができます。
# listのデータを、直接記述する方法
original_list = [1, 2, 3]
copied_list = [1, 2, 3]
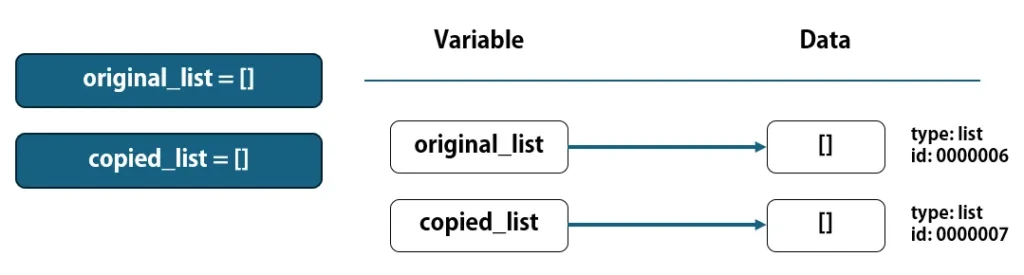
# 空のlistでも、違うデータとして作成される
original_list = []
copied_list = []
# スライスを使う方法
original_list = [1, 2, 3]
copied_list = original_list[:]
# copy()メソッドを使う方法
original_list = [1, 2, 3]
copied_list = original_list.copy()
1つ目は、copied_listに対して代入するlistやその要素を、直接記述する方法です。直接記述した場合、要素の中身が全く同じ内容でも、違うlistとしてデータを生成し、変数はそれぞれ違うデータを参照します。これは、空のlist([])の場合でも同じです。
2つ目は、スライスを使う方法です。スライスは、指定された範囲の要素を抽出して、新しいデータを作成するという処理になります。これは、全範囲抽出([:])の場合であっても同じです。
3つ目は、copy()メソッドを使う方法です。
同じ要素を持つlistを別データとして作成・参照させたい時は、上記3つの方法から選択します。
同じlistを参照してしまう方法と区別して扱えるようにしましょう。
コピー先のlistを編集すると、オリジナルのlistも変更される訳
それでは、本題の『コピー先のlistを編集するとオリジナルのlistも変更される』件について解説します。
copied_list = original_listとすると同じlistを参照するようになります。その後でcopied_list[0] = 99のようにlistの要素を編集すると、そのlistが他の変数から参照されているかどうかは調べられずに、『"copied_list"の参照先のlistの要素を編集する』という挙動になります。
original_list = [1, 2, 3]
copied_list = original_list
copied_list[0] = 99
print(original_list) # [99, 2, 3]
print(copied_list) # [99, 2, 3]
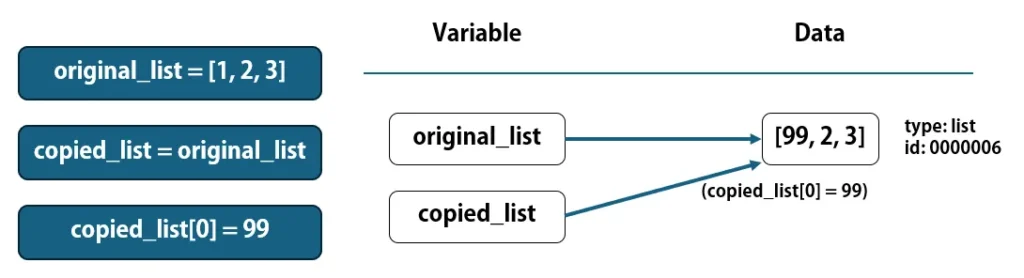
最後にprint出力する際は、それぞれが参照しているlistの情報を出力するため、listの要素が変更された後の[99, 2, 3]が表示されることになります。
スライス・copy()メソッドを使ってコピーしたlistの編集
スライス([:])もしくはcopy()メソッドを使うと、新しいlistが作成されて、それぞれの変数が違うlistを参照するようになります。そのため、copied_list[0] = 99のようにlistの要素を編集しても、他方の変数が参照しているlistは影響を受けません。
original_list = [1, 2, 3]
copied_list = original_list[:] # もしくは、"original_list.copy()"
copied_list[0] = 99
print(original_list) # [1, 2, 3]
print(copied_list) # [99, 2, 3]
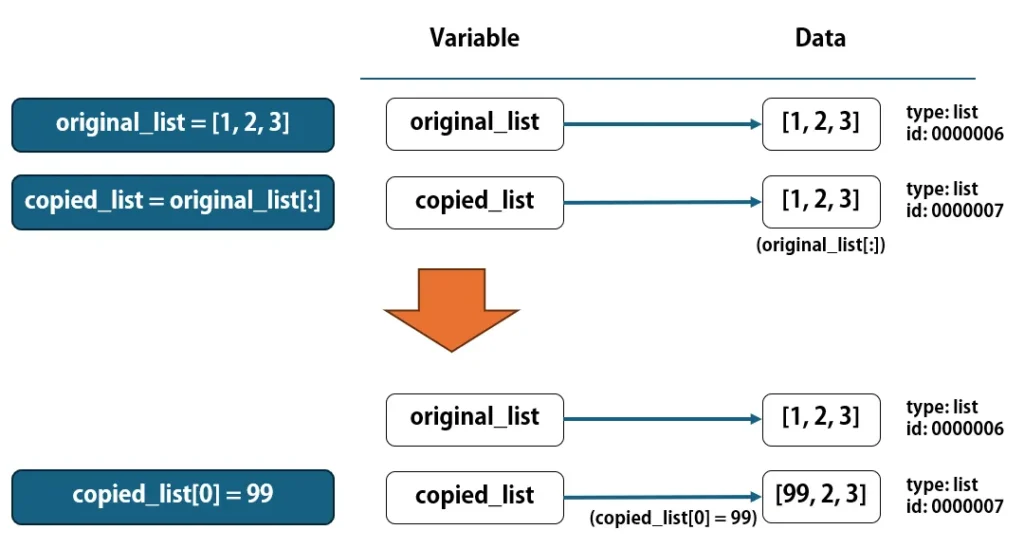
ネストされたlistの管理
それでは、ネストされた場合はどうでしょうか。残念ながら、スライス([:])やcopy()メソッドを使っても解決できない問題があります。ネストの問題と、その解決方法を順に見ていきましょう。
ネストされたlistのデータ管理の基本
まずはネストされたデータがどのように管理されているか確認しましょう。
original_list = [[1, 2]]
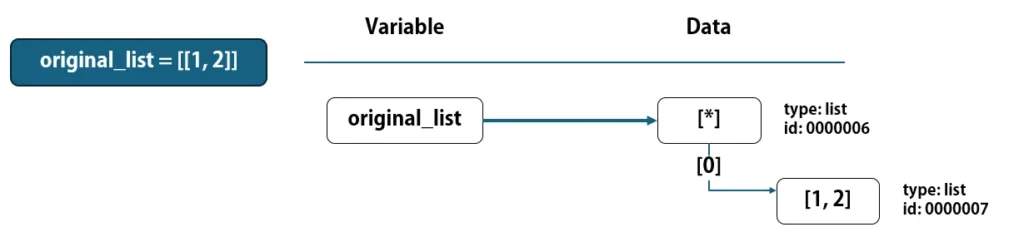
上記コードが実行されると、外側と内側のそれぞれのlistが生成されます。そして、上図のid: 0000006のlistは、要素番号[0]の要素としてid: 0000007のlistを紐づけて管理します。
次に、スライス([:])を使ってlistを複製した場合の挙動をみてみましょう。
original_list = [[1, 2]]
copied_list = original_list[:]
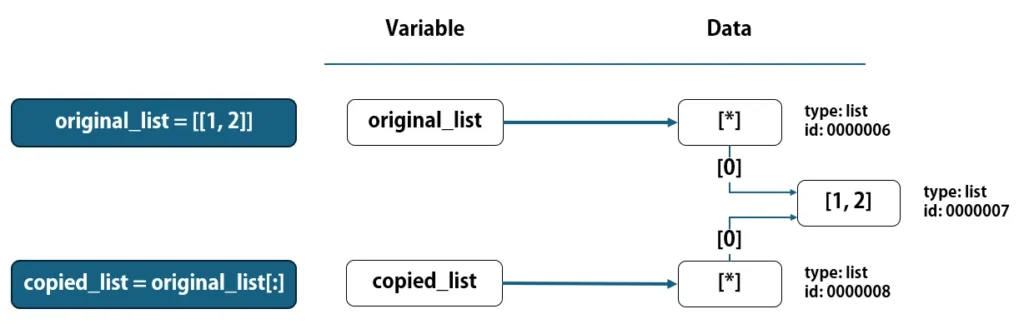
スライスを使うと、"original_list"が直接参照しているlistは複製されます。上図のように、"copied_list"の参照先のlistは、"original_list"が参照しているlistとは違うものになります。しかし、そのlist(id: 0000008)の要素番号[0]の参照先は、id: 0000007のlistになります。
つまり、スライスの場合、"内側"のlistは複製されずに、各変数が参照している、外側のlistの要素番号[0]の参照先として共有されることになります。これは、copy()メソッドを使った場合も同様です。
ネストされたlistに対する編集
次に、ネストされたlistに対する編集を行い、挙動を確認します。
次のコードは、copied_list[0][0]に対して編集を行っています。
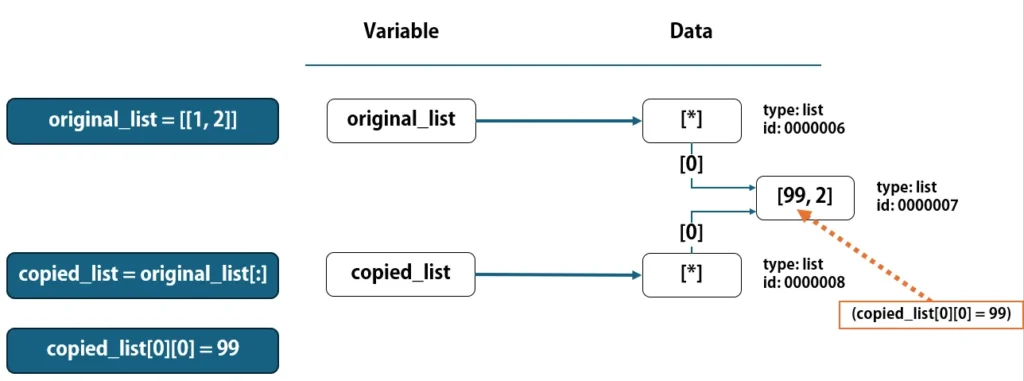
original_list = [[1, 2]]
copied_list = original_list[:]
copied_list[0][0] = 99
print(original_list) # [[99, 2]]
print(copied_list) # [[99, 2]]
コードを実行すると、両方とも[[99, 2]]と出力されます。
これは、copied_list[0]が参照しているlistとoriginal_list[0]が参照しているlistは同一のため、その参照先のlist(id: 0000007)の要素を変更すると、それぞれの変数の出力に影響が出てしまいます。
Shallow copy (シャローコピー) とDeep copy (ディープコピー)
Shallow copy (シャローコピー)
ここで、Shallow copy (シャローコピー)という用語について説明したいと思います。Shallow copyを日本語訳すると"浅いコピー"となるのですが、これは、listなどのオブジェクト(構造体など)を複製する時に"外側"のみ複製し、ネストされたオブジェクトについては元と同じ参照を維持するものです。つまり、スライス([:])やcopy()メソッドは、Shallow copyということになります。
Shallow copyのメリットとしては、外側のみ複製するので、メモリ使用量や処理速度にそれほど影響がないことが挙げられます。デメリットとしては、ネストされたオブジェクトはオリジナルのものと共有しているので、その中の要素を変更する場合は十分に注意する必要がある、という点が挙げられます。
Deep copy (ディープコピー)
Deep copy (ディープコピー)を日本語訳すると"深いコピー"となるのですが、これは、ネストされた構造体などのオブジェクトも含め複製し、完全に独立した状態のコピーを作ります。そうすることで、ネストされたlistへの編集が、他方に影響を与えずに済みます。デメリットとしては、複製するデータが大量にあると、メモリ使用量や処理速度に影響が出ることがある、という点が挙げられます。
Pythonでは、copyモジュールのdeepcopy()関数を用いることで、ネストされたデータも含め複製することができます。
import copy
original_list = [[1, 2]]
copied_list = copy.deepcopy(original_list)
copied_list[0][0] = 99
print(original_list) # [[1, 2]]
print(copied_list) # [[99, 2]]
deepcopy()関数を使うには、まずcopyモジュールをimportします。
そして、"original_list"の定義をした後、copied_list = copy.deepcopy(original_list)でネストされたlistを含め、複製を行います。下図のように、直接参照しているlistと、その要素として参照しているlistも複製されます。
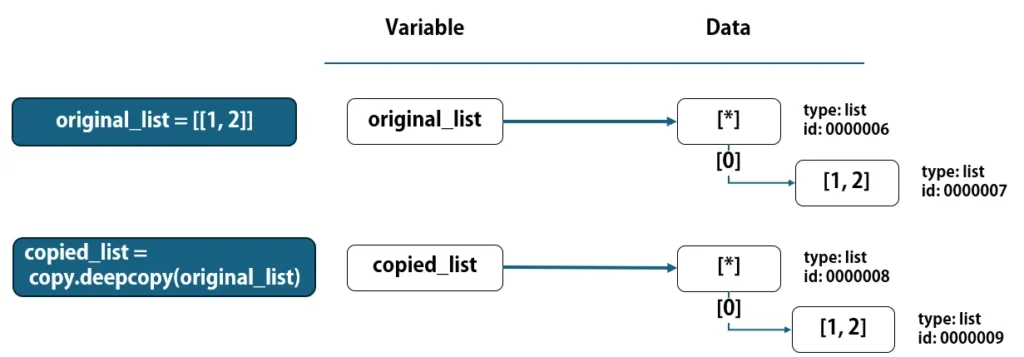
deepcopyを行った後でcopied_list[0][0] = 99を実行すると、オリジナルには影響を与えずに、ネストされたlistの要素に対して編集を行うことができます。
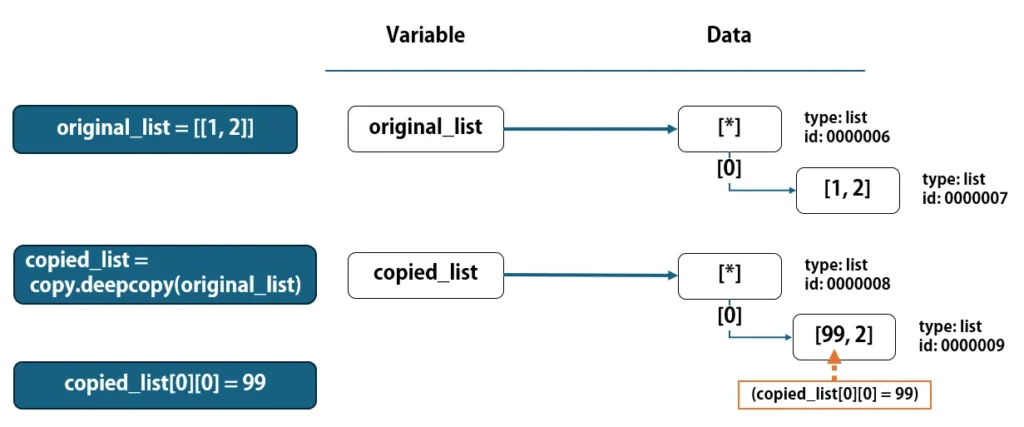
出力結果は、"original_list"が[[1, 2]]、"copied_list"が[[99, 2]]となり、他方のlistを変更せずに編集ができたことが確認できます。

![sec02 - listのコピー(2) [type() と id()]](https://python101.tech/wp-content/uploads/2025/08/eyecatch_185-300x169.webp)




